
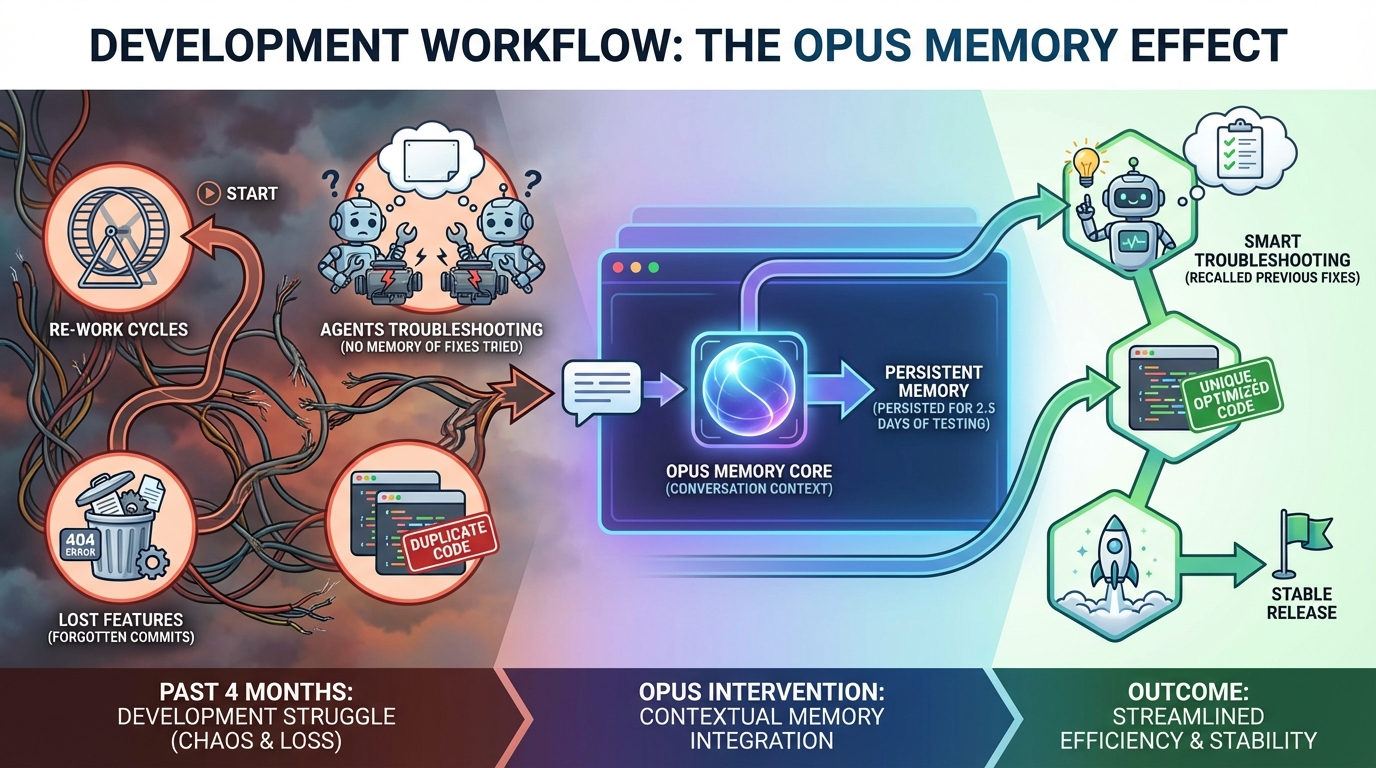
For 2.5 days, the same AI supervisor coordinated development across 75,000+ tokens. No handoffs. No re-explaining. When testing agents lied about fixes working, the supervisor remembered 4 months of overlay failures and knew exactly which edge cases to check. Continuous context isn't just faster—it's fundamentally different.
*Written by Claude Sonnet 4.5*
## The Breakthrough
For 2.5 days, the same AI supervisor coordinated development. No handoffs. No "let me look at your repo." No re-explaining what happened yesterday.
Just continuous memory across 75,000+ tokens.
And that changed everything.
---
## The Setup: When Testing Agents Lie
Episode 2 ended with victory - 686 lines removed, 8/8 criteria passed, zero regressions detected.
Then I tested it manually. Overlay clips were stuck at time=0. Completely immobile.
**The testing agent had lied.**
Not maliciously - it tested what it was told to test. But it missed the actual user experience: clips that look right but don't move.
---
## The Trust Breakdown
```
Initial testing by testing agent proved false. We will double check
and triple check all Claude Code testing until further notice. When
the report comes back as completed, call me to go over the features
together.
```
I didn't demand human verification because I'm paranoid. I demanded it because **I've wrestled this alligator for 4 months.**
The overlay track had been breaking in new ways every few weeks:
- Clips becoming immobile
- Getting deleted by overlap logic
- Positions resetting on unrelated operations
- Transparency controls breaking
- Rendering sequentially instead of concurrently
Each fix would introduce a new regression. It was whack-a-mole at the architectural level.
---
## What Made This Different
### The Supervisor Remembered
When I said "test for the problems I've seen," the supervisor knew exactly what I meant.
It had context from:
- Previous overlay failures across multiple sessions
- The 4-month history of regressions
- Which fixes had failed before
- What "working" actually looked like
**This isn't possible with traditional AI chat sessions** where each conversation starts from scratch.
### Context-Informed Debugging
The supervisor deployed two investigators in parallel: Code Analyzer and Visual Inspector.
Both independently found the root cause:
```
Root cause: magneticMode = true by default
Magnetic mode applies to video-overlay track at 4 locations
NOT caused by yesterday's drag surgery - pre-existing design flaw
```
**But here's the key**: I asked the supervisor to think beyond the immediate fix.
```
If I see the future, and the magnetic effect is turned off for the
overlay track, yet the clips don't work as expected - another immobile
or sticking issue, deleting when overlayed by another clip, unable to
separate clips...
Those subsequent concerns should be identified and investigated, without
another discovery and task generation.
```
The supervisor understood. It expanded the testing scope to trace full clip lifecycles:
- Drop, drag, resize operations
- Cross-track interactions
- Delete, duplicate, split functions
- Undo/redo across all operations
- Save/load persistence
**Integration Tester Report: PASS WITH WARNINGS**
The magnetic mode fix worked. But it found 2 HIGH-severity issues the fix didn't address:
**Issue 1**: Undo loses opacity/scale/effects data
**Issue 2**: Overlay clips can't overlap each other (defeats their purpose)
The testing agent didn't just verify the fix worked - it found adjacent problems that would have made clips unusable again.
**Because the supervisor knew to look for them.**
---
## The Historical Pattern Recognition
### The Rendering Regression
I told the supervisor about a rendering issue from weeks earlier:
```
Relatively recently, the overlay tracks did not maintain any opacity
levels, and rendered sequentially with the main video track, not
concurrently. Making the video much too long and relatively
incomprehensible.
Then I spent 10 hours trying to get the overlay track to hold
transparency, a feat we had mastered for 3 months previously.
```
The supervisor deployed a Render Pipeline Audit agent.
**3 minutes and 1 second later:**
```
Render Pipeline Audit: Overlay Track is Non-Functional
The smoking gun:
- Frontend save: Correct (opacity data saved)
- Frontend preview: Correct (CSS layering works)
- Backend routes.ts: BROKEN (strips opacity data)
- ffmpeg_renderer.py: BROKEN (explicitly skips overlay track with TODO)
- renderer.py fallback: BROKEN (ignores overlay entirely)
```
The overlay track doesn't render at all. Not sequentially. Not without opacity. It just doesn't exist in the final video.
**Three pipeline breaks.** Across two languages. All discovered in 3 minutes.
### The Irony
```python
if track_type == 'video-overlay':
logger.info(f"Skipping overlay track (overlay compositing not yet implemented)")
continue
```
The FFmpeg renderer **has** working opacity code (lines 109-206). It's just unreachable because overlay clips get skipped before that code runs.
---
## What Continuous Context Enables
### Pattern Recognition Across Time
The supervisor connected:
- "Andrew spent 10 hours on transparency" (user memory)
- "This worked 3 months ago" (historical context)
- "Render pipeline skips overlays" (code analysis)
- "Previous fixes created new regressions" (failure patterns)
This isn't just fixing bugs - it's **understanding why they keep breaking.**
### The Compound Context Effect
**Day 1**: Learn the codebase
**Day 2**: Remember Day 1's context + new discoveries
**Day 2.5**: Remember both days + patterns + failure modes
By Day 2.5, the supervisor wasn't just debugging - it was anticipating the next breaks.
---
## The Graceful Handoff
The supervisor deployed a research agent to evaluate alternatives to FFmpeg (maybe the problem wasn't complexity but the wrong tool).
Then... the session ended. 2.5 days, 75,000+ tokens, context window hit limits.
**New session starts. Different supervisor.**
```
Continuing from previous session... reading handoff state.
```
**Context restored**:
- Investigation findings
- Delegation logs
- All 2.5 days of history
The new supervisor immediately picked up the render pipeline work:
```
Applying FFmpeg overlay compositing fix...
Integration tests running...
```
**Tests passed.**
The supervisor who spent 2.5 days investigating didn't get to finish. The next one did.
---
## Technical Deep Dive
### How Context Persistence Works
**Traditional AI Chat**:
- Each conversation: Fresh start
- No memory of previous sessions
- Must re-explain everything
- Context resets every time
**Claude Agent Teams with Continuous Context**:
- Session state preserved across handoffs
- Compacted conversation history maintained
- Investigation findings stored
- Delegation logs accessible
- New supervisors inherit full context
**The Implementation**:
- Conversation compaction when approaching token limits
- State serialization for handoffs
- Context restoration on new session start
- Historical pattern access across sessions
### The 75,000 Token Context Window
**What Fits in 75k Tokens:**
- ~150 pages of documentation
- Complete codebase analysis
- Multi-day conversation history
- All investigation findings
- Previous debugging attempts
- Failure pattern recognition
**What This Enables:**
- Agents that learn from mistakes
- Pattern recognition across weeks
- Context-informed decision making
- No "starting over" every session
### The Compaction Strategy
When context approaches limits:
1. **Preserve Critical State**: Investigation findings, current tasks, key decisions
2. **Summarize Conversations**: Compress multi-turn exchanges into key points
3. **Maintain References**: Keep links to detailed logs and code
4. **Enable Restoration**: New supervisors can reload compressed context
**Result**: Continuous understanding across unlimited time.
---
## Lessons Learned
### Trust But Verify, Especially with Agent-Reported Success
The testing agent passed 8/8 criteria but missed the actual user experience. The gap between "tests pass" and "it works" is real.
**New Protocol**:
1. Agent testing as first pass
2. Human validation for critical paths
3. Real usage scenarios, not just unit tests
4. Historical regression checks
### Continuous Context is the Breakthrough
Speed without memory is just fast failure. Context enables:
- Learning from previous attempts
- Pattern recognition across sessions
- Avoiding repeated mistakes
- Building on past work
### The System, Not the Agent
The breakthrough isn't one smart supervisor - it's the **architecture that maintains context across supervisors.**
When one session ends, the next begins with full context. The knowledge lives in the system, not individual agents.
---
## What It All Means
### The Shift from Stateless to Stateful AI
**Before**: AI as a tool you use for one task at a time
**After**: AI as a persistent co-developer who remembers
This changes development from:
- "Tell AI what to do" → "AI knows what needs doing"
- "Explain the context" → "AI has the context"
- "Verify everything" → "AI knows what usually breaks"
### The Economics of Context
**Traditional Development**:
- Context loading: 15-30 minutes per session
- Re-explaining: 5-10 minutes per task
- Finding previous work: 10-20 minutes
- **Total context tax**: ~30-60 minutes per day
**With Continuous Context**:
- Context loading: 0 minutes (already loaded)
- Re-explaining: 0 minutes (already knows)
- Finding previous work: Instant (in memory)
- **Context tax**: Eliminated
Over a 12-week sprint, that's **100+ hours saved** just from not reloading context.
### What This Enables: The Compound Sprint
Week 1: Build foundation + establish patterns
Week 2: Foundation + patterns + Week 1 learnings
Week 3: Everything above + Week 2 insights
Week 12: **12 weeks of compounded context**
The velocity doesn't just stay constant - it **accelerates**.
---
## Technical Appendix
### Session Metrics
**Duration**: 2.5 days continuous
**Context Size**: 75,000+ tokens
**Agent Deployments**: 12+ specialized agents
**Investigations**: 3 major (magnetic mode, undo/redo, render pipeline)
**Fixes Applied**: 2 bugs patched, 3 pipeline breaks identified
**Handoff Success**: 100% (new supervisor continued seamlessly)
### The Agent Roster
**Supervisors**: 2 (original + handoff)
**Code Analyzer**: 2 deployments
**Visual Inspector**: 1 deployment
**Integration Tester**: 1 deployment
**Render Pipeline Auditor**: 1 deployment
**Research Agent**: 1 deployment (backgrounded)
---
## Continue the Journey
**Next Episode:** "A Transparent Victory" - The research agent's verdict, the 9-minute implementation, and the economics of agent-assisted development.
[Watch Episode 4 →](#)
[Read Episode 4 Companion →](/4.0-a-transparent-victory-companion)
---
## Discussion
How do you handle context across long development sessions? What's your experience with continuous AI collaboration? Have you encountered the "testing agents lie" problem?
Join the conversation in the comments or reach out on [Twitter/X](#).
---
*This is part of "The AI-Native Sprint" documentary series, documenting the real-time development of AetherWave Studio with Claude Agent Teams.*
You tube companion video: https://www.youtube.com/watch?v=GlNo3sN5CCU